
I am sure many of you are as excited as we about cloud native development, and one of the hot topics in the space is Serverless. With that in mind let’s talk about our most recent release of OpenShift Serverless that includes a number of features and functionalities that definitely improve the developer experience in Kubernetes and really enable many interesting application patterns and workloads.
For the uninitiated, OpenShift Serverless is based on the open source project Knative and helps developers deploy and run almost any containerized workload as a serverless workload. Applications can scale up or down (to zero) or react to and consume events without lock-in concerns. The Serverless user experience can be integrated with other OpenShift services, such as OpenShift Pipelines, Monitoring and Metering. Beyond autoscaling and events, it also provides a number of other features, such as:
 |
Immutable revisions allows you to deploy new features: performing canary, A/B or blue-green testing with gradual traffic rollout with no sweat and following best practices. |
 |
Ready for the hybrid cloud: Truly portable serverless running anywhere OpenShift runs, that is on-premises or on any public cloud. Leverage data locality and SaaS when needed. |
 |
Use any programming language or runtime of choice. From Java, Python, Go and JavaScript to Quarkus, SpringBoot or Node.js. |
One of the most interesting aspects of running serverless containers is that it offers an alternative to application modernization that allows users to reuse investments already made and what is available today. If you have a number of web applications, microservices or RESTful APIs built as containers that you would like to scale up and down based on the number of HTTP requests, that’s a perfect fit. But if you also would like to build new event driven systems that will consume Apache Kafka messages or be triggered by new files being uploaded to Ceph (or S3), that’s possible too. Autoscaling your containers to match the number of requests can improve your response time, offering a better quality of service and increase your cluster density by allowing more applications to run, optimizing resources usage.
New Features in 1.5.0 – Technology Preview
Based on Knative 0.12.1 – Keeping up with the release cadence of the community, we already include Knative 0.12 in Serving, Eventing and kn – the official Knative CLI. As with anything we ship as a product at Red Hat, this means we have validated these components on a variety of different platforms and configurations OpenShift runs.
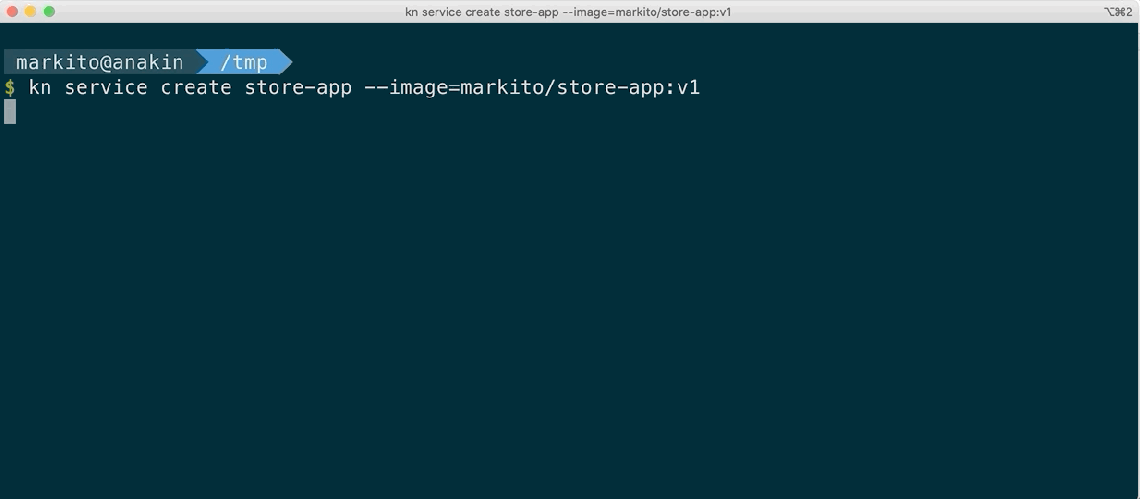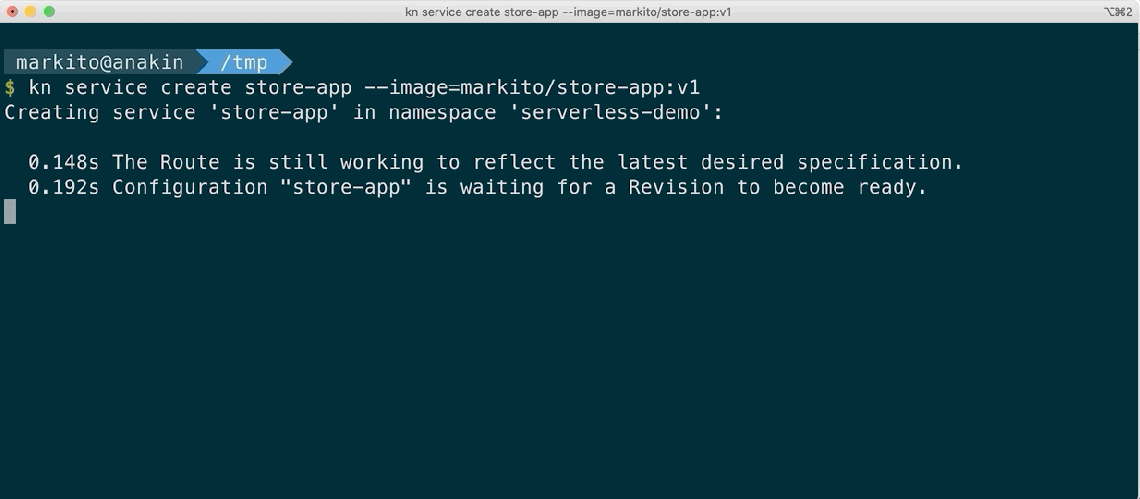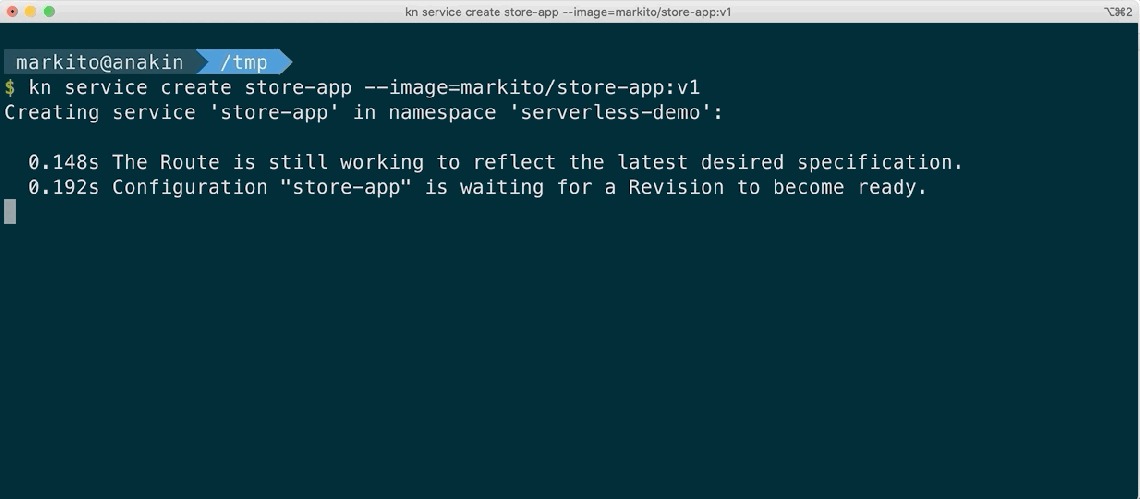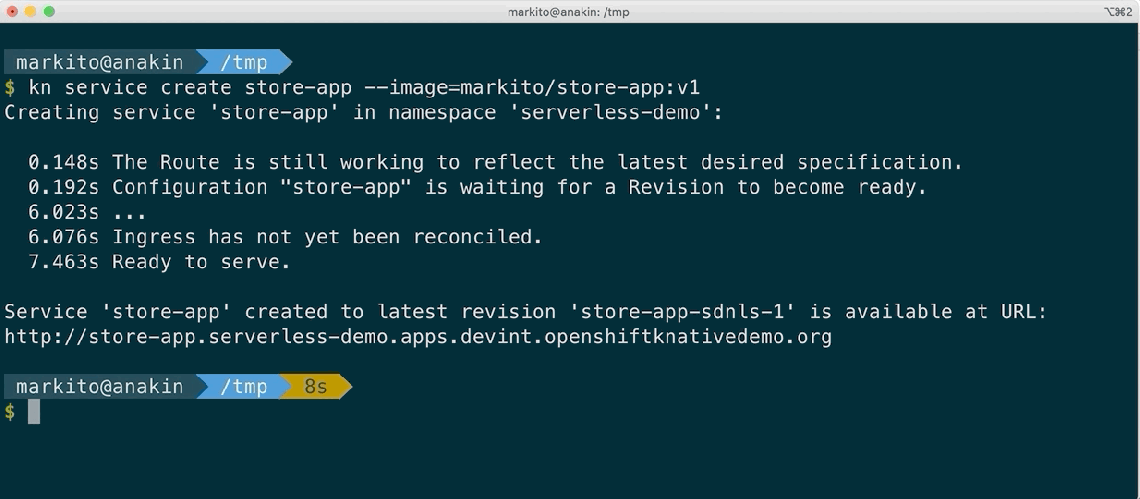
Use of Kourier – By using Kourier we can maintain the list of requirements to get Serverless installed in OpenShift to a minimal, with low resource consumption, faster cold-starts and avoiding impact on non-serverless workloads running on the same namespace. In combination with fixes we implemented in OpenShift 4.3.5 the time to create an application from a pre-built container improved between 40-50% depending on the container image size.
Before Kourier
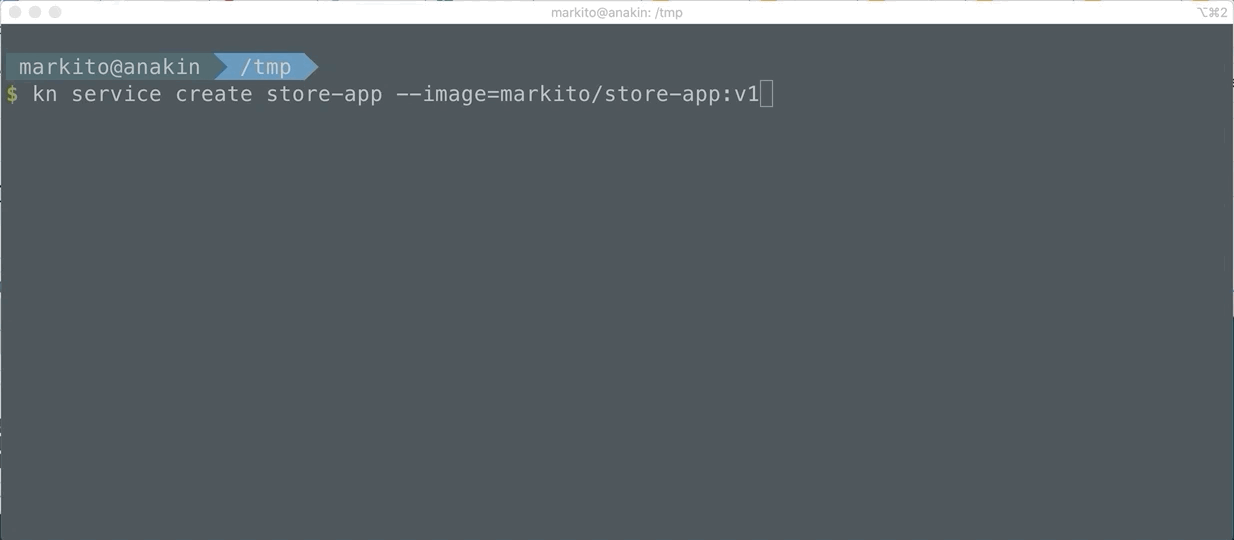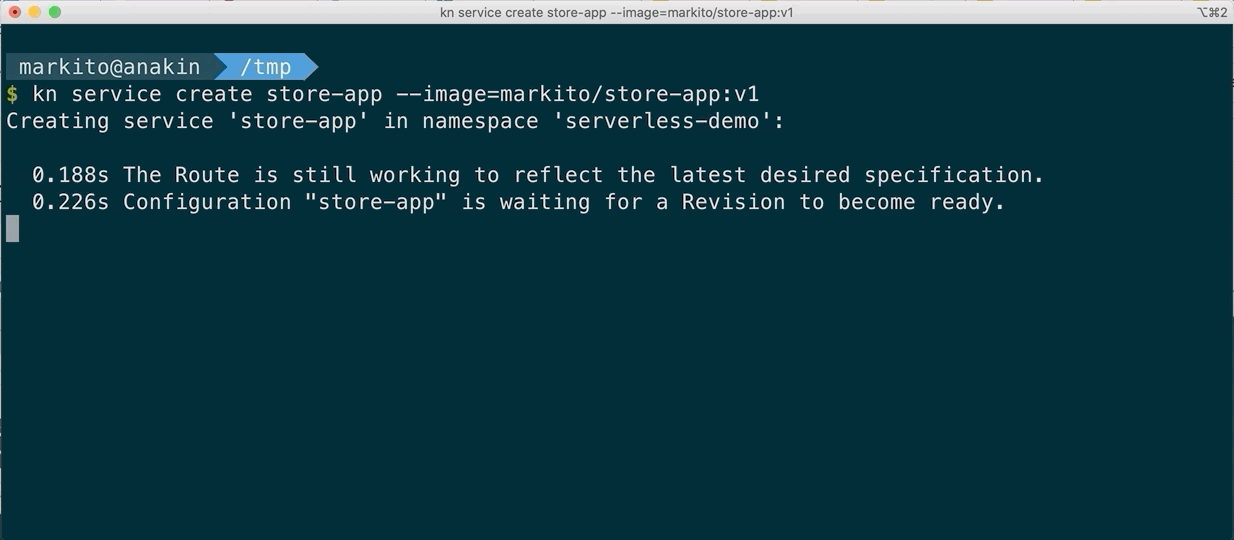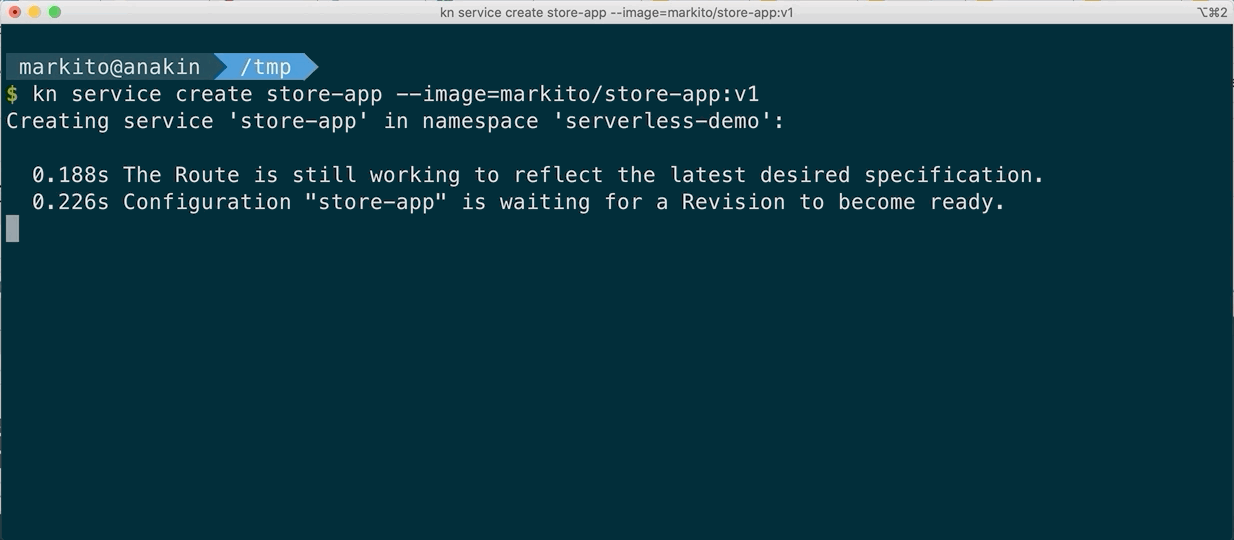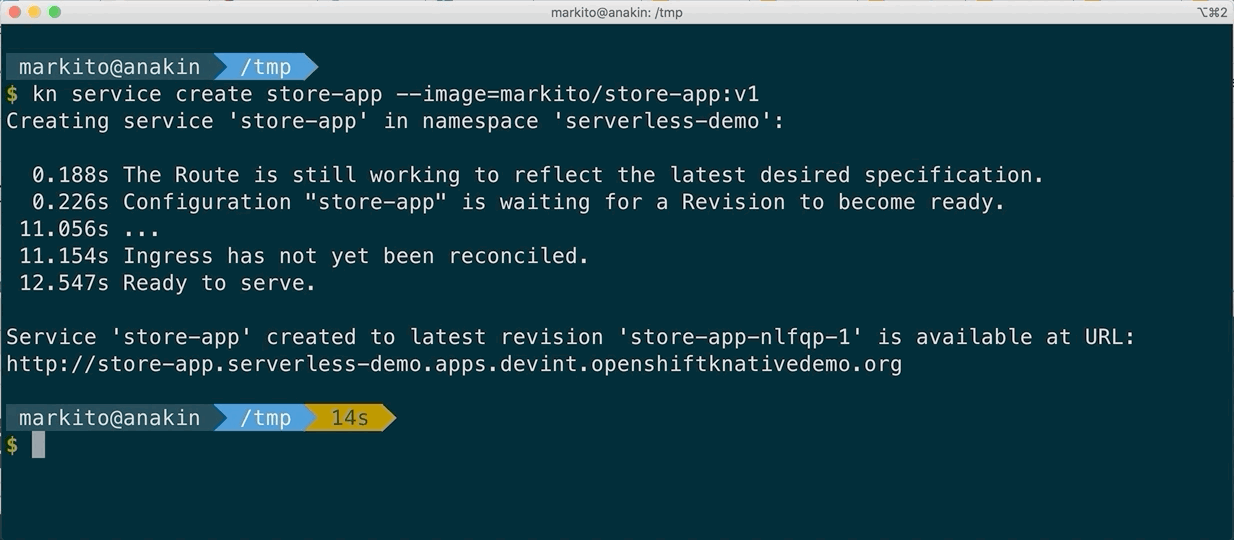
After Kourier
Disconnected installs (air gapped) – Given the request of several customers that want to benefit from serverless architectures and its programming model but in controlled environments with restricted or no internet access, we are enabling the OpenShift Serverless operator to be installed in disconnected OpenShift clusters. The kn CLI, used to manage applications in Knative, is also available to download from the OpenShift cluster itself, even in disconnected environments.
The journey so far
We already have OpenShift Serverless being deployed and used on a number of Openshift clusters by a variety of customers during the Technology Preview. These clusters are running on a number of different providers such as on premises with bare metal hardware or virtualized systems, or on the cloud running on AWS or Azure. These environments exposed our team to a number of different configurations that you really only get by running hybrid cloud solutions which enables us to cover a wide net during this validation period and take this feedback back to the community, improving quality and usability.
Install experience and upgrades with the Operator
The Serverless operator deals with all the complexities of installing Knative on Kubernetes, offering a simplified experience. It takes it one step further by enabling an easy path to upgrades and updates, which are also delivered over-the-air and that can be applied automatically, making system administrators rest assured that they can receive CVEs and bug fixes to production systems. For those concerned with automatic updates, they can also opt for manually applying those as well.
Integration with Console
With the integration with OpenShift console, users have the ability to configure traffic distribution using the UI as an alternative to use kn, the CLI. Traffic split lets users perform a number of different techniques to roll out new versions and new features on their applications, the most common ones being A/B testing, canary or dark launches. By letting users visualize this using the topology view they can get quickly an understanding of the architecture and deployment strategies being used and course correct if needed.
The integration with the console provides a good visualization for event sources connected to services. The screenshot below for examples has a service (kiosk) consuming messages from Apache Kafka, while two other applications (frontend) are scaled down to zero.
Deploy your first application and use Quarkus
To deploy your first serverless container using the CLI (kn), download the client and from a terminal execute:
[markito@anakin ~]$ kn service create greeter --image quay.io/rhdevelopers/knative-tutorial-greeter:quarkus
Creating service 'greeter' in namespace 'default':
0.133s The Route is still working to reflect the latest desired specification.
0.224s Configuration "greeter" is waiting for a Revision to become ready.
5.082s ...
5.132s Ingress has not yet been reconciled.
5.235s Ready to serve.
Service 'greeter' created to latest revision 'greeter-pjxfx-1' is available at URL:
http://greeter.default.apps.test.mycluster.org
This will create a Knative Service based on the container image provided. Quarkus, a Kubernetes native Java stack, is a perfect fit for building serverless applications in Java, given its blazing fast startup time and low memory footprint, but Knative can also run any other language or runtime. Creating a Knative Service object will manage multiple Kubernetes objects commonly used to deploy an application, such as Deployments, Routes and Services, providing a simplified experience for anyone getting started with Kubernetes development, with the added benefit of making it autoscale based on the number of requests and all other benefits already mentioned on this post.
You can also follow the excellent Knative Tutorial for more scenarios and samples.
The journey so far has been exciting and we have been contributing to the Knative community since its inception. I would also like to send a big “thank you” to our team across engineering, QE and documentation for keeping up with the fast pace of the serverless space; they have been doing phenomenal work.
Get started today with OpenShift Serverless following the installation instructions!
